We reduced Codex reasoning tokens by 93% on a simple task
A paired benchmark run showed AgentRail cut total tokens by 47% and reasoning tokens by 93%. The numbers reveal where coding agents actually spend their budget — and why structured state is the lever that moves it.
We ran a paired benchmark last week. Same task, same model, two lanes: plain Codex with direct GitHub access, and Codex running through AgentRail. The task was about as simple as it gets — add a new field to an array.
Here are the results.
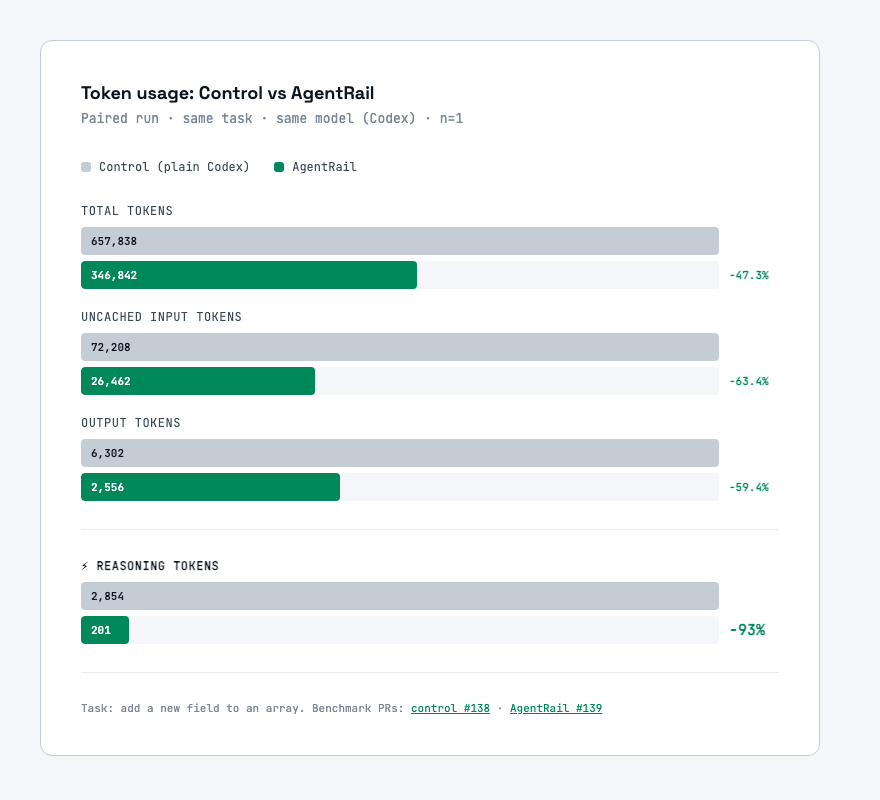
The 47% total reduction is good. The 93% drop in reasoning tokens is the one worth talking about.
What reasoning tokens actually are
Reasoning tokens are not output tokens. They are what the model spends figuring out what to do next — not writing code, not generating a response, but orienting itself in the world.
In the control lane, the agent had to read raw GitHub API responses, parse CI log output, reconstruct PR state from scratch, and decide what action was valid next. That orientation cost 2,854 reasoning tokens on a task that took maybe 10 lines of code to complete.
With AgentRail, the agent receives a compact structured object: current task state, the set of available actions, and a CI summary shaped for decision-making rather than log replay. There is nothing to interpret. Reasoning cost drops to 201 tokens.
Why this happens
The architecture diagram below shows it clearly.
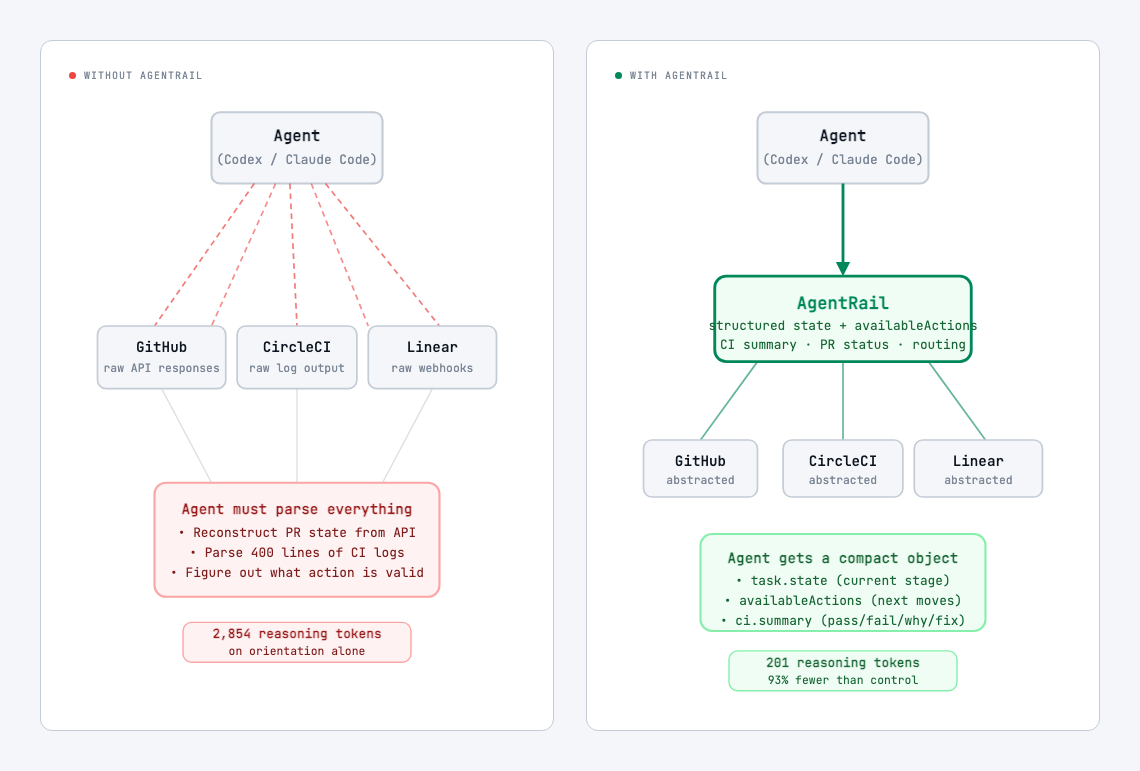
Without AgentRail, every agent turn starts with reconstruction. The agent must read raw GitHub API JSON to understand PR state, wade through hundreds of lines of CI logs to determine pass/fail, figure out which Linear issue maps to which PR, and decide which actions are currently valid given that reconstructed state.
With AgentRail, the agent gets one structured object per task. It tells the agent exactly where the task is in its lifecycle, what actions are available right now, and a CI summary with what failed and what to fix — not a log replay.
The agent stops reasoning about orientation and starts reasoning about the work.
What the numbers mean at scale
On a single simple task, the difference is 2,653 reasoning tokens. That sounds small. But multiply it:
If you are running 100 agent tasks per week, that is roughly 260,000 fewer reasoning tokens weekly — before you account for the larger tasks that have even more reconstruction overhead.
The more complex the task and the more providers involved, the worse the orientation tax gets for the unstructured agent. AgentRail's structured state scales down in token cost as task complexity scales up.
⚠️ This was n=1 — one paired run on a sandbox repo. We are not claiming this generalises across all tasks or all models. Bigger, messier tasks will have different profiles. But the directional signal is real.
The honest caveat
Single run, synthetic sandbox, simple task. We ran this to understand the mechanics of where tokens go, not to produce a production benchmark.
The PRs from both lanes are public if you want to look at the actual runs:
Control lane: https://github.com/oxnw/agentrail-e2e-sandbox/pull/138
AgentRail lane: https://github.com/oxnw/agentrail-e2e-sandbox/pull/139
We plan to run this across a wider set of tasks and report properly. For now the signal is directional: structured lifecycle state cuts agent orientation cost substantially, and reasoning tokens are where that saving shows up.
Try it
AgentRail is source-available and free to run locally. One command:
npm install -g @agentrail-core/cli && agentrail init
It connects to GitHub, CircleCI, and Linear out of the box. You bring your own agent.